

| ITEC 325 |
| 2016fall |
| ibarland |
|
|
|
home—lects—hws
D2L—breeze (snow day)
Originally based on XML Visual Quickstart Guide by Kevin Howard Goldberg
In the 80s, SGML was an obscure markup language; Tim Berners-Lee based HTML on it in 1990, which by the mid-90s was widely known. But because early browsers, trying to get market share, all worked hard to make sense of ill-formed HTML pages (tag soup), which in turn led people to learn and write bad HTML, the standardization process came to allow all sorts of awful shortcuts (e.g. you don't need to put attributes in quotes, or close your p tags, etc.).
In reaction to the sorry state of HTML, XML was a reiteration (and narrowing) of SGML.
As always: for your web pages, I recommend using all XML conventions when writing your HTML5. Even though you technically don't need to (say) close your p tags in HTML5, the XML requirements are all good ones which help clean data and interoperability.
Here are some specific examples:
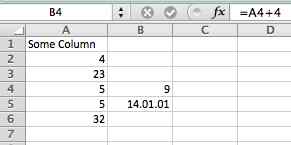 (view the spreadsheet's xml)
(view the spreadsheet's xml)
(As an aside: vector graphics vs. bitmap graphics: What are pros and cons of each? For sound, compare: Beethoven's Fifth on piano, vs. Beethoven's Fifth on piano.)
Keeping data in XML format has several nice properties:
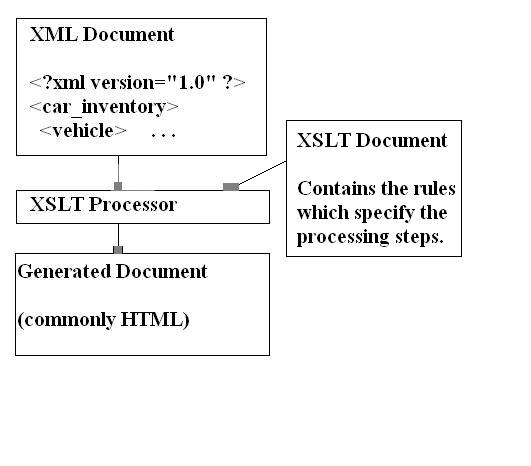
The next step in learning to use XML is understanding how to format these documents. The details for formatting XML documents was originally in a specification called XSLT, which stands for eXtensible Style Language Transformations. Chapters 2-4 explain how to use XSL to transform XML documents. The end result might be another XML document, or an HTML document (most common). You can transform an XML document into practically any document type.
Transforming an XML document means taking in one XML tree and producing another — a function from XML trees to XML trees. For example, consider the input
<my_children> <child> <name>Logan</name> <gender>M</gender> <age>7</age> </child> <child> <name>Rebecca</name> <gender>F</gender> <age>3</age> </child> <child> <name>Lee</name> <gender>F</gender> <age>2</age> </child> </my_children>An XSLT program might take this and return a new XML tree:
<html>
<body>
<h3>Some Kids</h3>
<ul>
<li>Logan, who is 7</li>
<li>Rebecca, who is 3</li>
<li>Lee, who is 2</li>
</ul>
</body>
</html>
Rather than write such a function in Java or a general-purpose programming language, XSLT is a domain-specific language, specifically invented to make these tree-transformations easy to write. XSLT can be used to reorder the ouput according to user established criteria, display only portions of the document, and more.
<xsl:for-each select="nodeSpec">
results...
</xsl:for-each>
|
<?xml-stylesheet type="text/xsl" href="foo.xsl"?>
|
Once the browser has constructed the XML data tree, it then transforms that XML tree using the XSLT instructions, yielding a new tree. The transformation rules are called “templates”; they correspond to functions in a programming language — a function which is given an XML node as input, and returns a (new) XML node.
(Note: usually the output happens to be XHTML, but it can in theory be any XML.)
A particular transformation (“template”)
looks at one node of the input tree [including its subtree],
and produces a (sub)tree to include in the overall output.
In the my_children example above,
there might be one “helper” XSLT template which,
given a
In our context, it's the browser which invokes the XSLT processor, and the result is html. (The XSLT is being run client-side.) However, that's not required — XSLT can produce any XML output, and the XSLT processing can be run stand-alone.
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
|
</xsl:stylesheet> |
<xsl:template match="/" >
<!-- rule for root-element here -->
</xsl:template>
|
Note:If you do not include a root template in the XSLT stylesheet, a root template built in to XSLT will be used (typically not what you want).
After running the XSLT program, we have newly-built XML tree;
the very last step is to flatten that tree back to a string
and print it as output.
We can use the
In 95% of all cases, our resulting XML tree is HTML, and so we'll include
<xsl:output method="html"/>
|
Note that
Example: Putting the above together, we should now be able to understand the previous example (oneWonder.xml and oneWonder.xsl).
The body of the loop is XSLT,
where the implicit-root of any relative XPATHS is
one of the things selected by the
Note how the syntax of
<p>
This person is
<xsl:choose>
<xsl:when test="height > 200">
extremely
</xsl:when>
<xsl:when test="height != 0">
<xsl:value-of select="height"/> cm
</xsl:when>
<xsl:otherwise>
unknown
</xsl:otherwise>
</xsl:choose>
tall.
</p>
|
<xsl:if test="boolean expression">
<!-- other XSLT statements statements -->
</xsl:if>
|
<xsl:if test="name[@language='English']">
It's called <xsl:value-of select='name'>.
</xsl:if>
|
observation: Placing thexsl:sort tag as the first-child inside the loop's body is definitely odd. It would be more natural to have a stand-alonesort tag which takes the XPATH of the nodes to sort, and returns a “list” of the sorted nodes. Or, the loop's control-flow should all be set via attributes. Alas, they didn't ask me when designing it. (There is actually a vague scoping reason for their design choice: there are XPATH issues since thexsl:for-each is working on the parent node, but the sort'sselect expression is relative to a child. In most langauges this is solved viasort being passed a function, and that function knows it will handle the individual-element type.)
Suppose we want each Wonder to be a link —
that is instead of the plain text “
<a>
<xsl:attribute name="href">
#<xsl:value-of select="name" /> <!-- link-target -->
</xsl:attribute>
<xsl:value-of select="name" /> <!-- link-text -->
|
The general syntax is clear from the preceding example:
<xsl:attribute name="att_name">
<!-- Here, specify the value of the new attribute.
Of course, you can use any XML: literal, or and XSLT instructions.
This body gets spliced into the enclosing tag (!) -->
</xsl:attribute>
|
(Like
Note: Thexsl:attribute tag must be the first child within the tag you're trying to affect. If we swapped thexsl:value-of andxsl:attribute nodes within thea , nothing renders at all. (There is no deep conceptual reason for this restriction.)
In the above example, note that although the code happens to work, it is not actually valid:
the value of the
An xslt short-cut: curly-braces
In XSLT, curly-brackets are interpreted as an xpath expression.
This provides a quick-and-dirty way to avoid
This shortcut
that works particularly well when generating attributes:
rather than requiring
Note: We will not emphasize this feature, in this course. Even though abstracting-into-a-function is one of the most fundamental aspects of programming, it's a bit unwieldy (and non-intuitive, and therefore not-particularly-common) to do so in XSLT. (Besides, our interest in XSLT is more as a vehicle to introduce the domain-specific languages xpath and DTDs, rather than than the language XSLT itself.)
The root template is the first thing processed in an XSLT style sheet. XSLT allows you to create more templates than just the root template. This allows you to create different sets of processing rules to apply to different parts of the XML document.
One of the main benefits of using templates is the ability to reuse a template for other nodes in your document. In the same way that one can use functions in most programming languages, you would create a template, and simply apply that template whenever necessary. This eliminates the need to repeat the same processing instructions.
In our ongoing example: We have been putting the non-english name in parentheses and italics. Suppose we want to do that throughout, consistently, and make it easy to maintain any changes or tweaks to this decision. We can define a template to process non-English name nodes, and then apply it in different contexts. (E.g. if there are tags for “newspaper”, we could apply the same template for non-English names there.)
<!-- Define the function -->
<xsl:template match="name[@language!='English']">
(<em><xsl:value-of select="."/></em>)
</xsl:template>
|
The system looks for and calls the template for "/" automatically;
other templates are only invoked via
There is a default template that gets called, if one doesn't otherwise apply:
For a text node, just return the text;
for a tag node, recursively call
You can't provide other arguments to templates — just the xpath of the element to process. And you can't call templates on any ol' node — you must specify (when you create the template) what xpaths it applies to.
<xsl:apply-templates select="ancient_wonders/wonder">
<xsl:sort select="height" order="descending" data-type="number" />
</xsl:apply-templates>
|
Similar to how a web-page (data) can have a css-stylesheet directive (processing), XML data files have a xml-stylesheet tag, with what XSLT file processes them.
It's annoying, that the
// The file children.php:
<?xml-stylesheet type="text/xsl" href="children.xsl"?>
<?php
require('children-data.xml');
?>
|
That is: Invoking XSLT via php.
So far, the XSLT we've seen is running client-side:
the client requests the .xml file,
it sees the
Note: If you run locally, not using a web-server at all, and opening via Open File…: Chrome won't work; Firefox will.
But of course, there's nothing inherent about doing the processing there. You can create a server-side .php page which, when requested, does the processing, to create the final html result:
Discussion:
You can do this in php as follows:
First, omit the
<?php
// Load XML file
$xml = new DOMDocument;
$xml->load('xml-database.xml');
// Load XSL file
$xsl = new DOMDocument;
$xsl->load('xsl-program.xsl');
// Configure the transformer
$proc = new XSLTProcessor;
// Attach the xsl rules
$proc->importStyleSheet($xsl);
echo $proc->transformToXML($xml);
?>
|
a missed opportunity?:Observe, in the last three lines, that you can can make one
XSLTProcessor object which transforms many XML files, all using the same stylesheet.If you're only serving a single web-page, this is usually moot. However, you may have php prorams that pre-generate many pages, which use case do you think would be more common?
- You have one XML file, and you want to create several views of it (run several different XSLT programs on the same data).
- You have one view (XSLT program), and want to apply it to many XML files. Those XML files must all have the same/similar tags, since XSLT programs are highly coupled to the tags they process.
1Although XML only became widespread in the 90s, old Lispers will look and say
S-expressions? Yes, of course they're an awesome data format!↩
Requring a tag at the start of every list? Sure, do that if you need to, I guess.
Repeat the tag at the end of every list? Well, that's sure redundant!
2Don't try editing the file w/o make a copy of the file and probably the .itl (real library file) as well. ↩
3 Remember, one of the XML requirements is that there is exactly one top-level tag. ↩
4
The reason for the lack of
5
Perhaps they should use an English term beside “if”;
perhaps
6
In php it's no problem to have an expression whose result
was inserted into the middle of an attribute.
However, since XSLT is itself written in XML,
and XML of course doesn't allow opening a tag in the middle of an attribute,
the syntax physically precludes putting
7 When rending a local file:// URL, Chrome's XSLT engine sees the stylesheet's URL (if also local) as a security risk, and does not open it. ↩
home—lects—hws
D2L—breeze (snow day)
| ©2016, Ian Barland, Radford University Last modified 2016.Nov.18 (Fri) |
Please mail any suggestions (incl. typos, broken links) to ibarland |
 |
{kind=link}